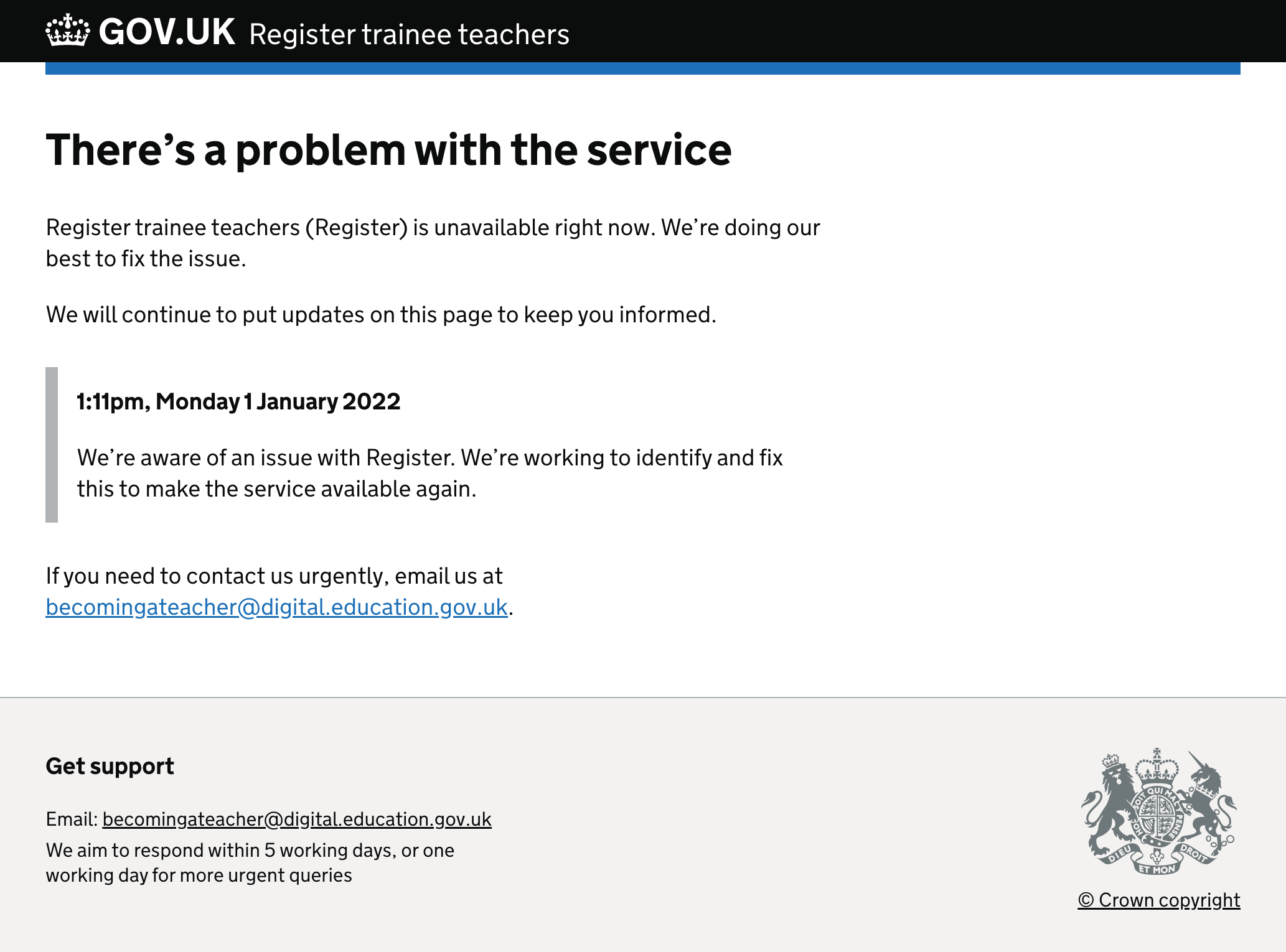
This post is about our ‘maintenance page’ — colloquially known as our ‘everything’s gone wrong page’. This is a page to be used when the entire service is down, either for maintenance or because something has gone very wrong.
Services should be prepared with one of these before they need one.
Why have a maintenance page
No services have 100% uptime. They all go down at some point. Sometimes planned, sometimes because of incidents. During these times, it’s better to show a helpful message acknowledging the issue rather than a cryptic unstyled error.
When a service goes down the developers on the service will be busy trying to get it back up. They won’t have time to create error pages to show, so teams need to have a page ready in advance.
What makes our maintenance page different
The page is based on the Design System’s service unavailable pattern.
An important implementation detail is the page is standalone from our app. It does not depend on our app or assets functioning to work. This could be important depending on what has broken about the service. It’s important the maintenance page does not depend on anything else except hosting.
In our case, the html and assets are stored in the same place as our production codebase, but deployed separately and manually.
Keeping users up to date
In the previous week, Register had an incident that brought the service down for 4 hours and 30 minutes. We deployed our maintenance page soon after the incident started, with the following message:
As the day went on, we wanted to let users know we were still investigating. We had already emailed all users about the unexpected incident, but we did not want to email users every time we had an update. We wanted updates to be easily accessible, rather than using emails where we could miss anyone not on our email list, and might risk annoying users with repeated emails.
The default service unavailable page doesn’t give any indication of when the message was first put up or if anything new has happened. Status pages from companies like Slack, have regular messages keeping users informed.
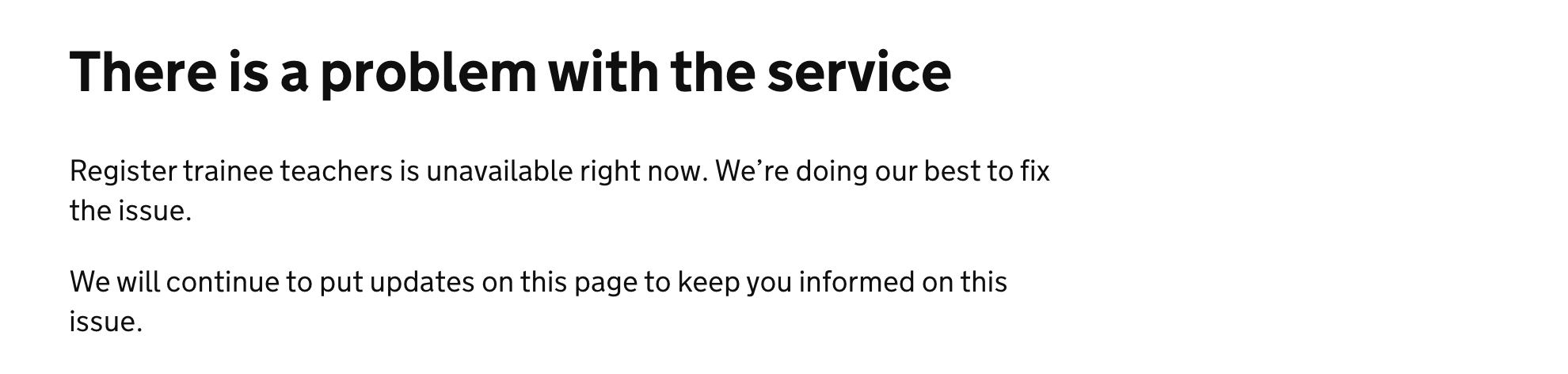
We decided to add a time-stamped update in a similar style to other commercial services’ status pages:

We think having a time-stamped update is a helpful way of showing the message is recent and that the team is aware of the issues. We’ve added it to our standard maintenance page.
October is a busy time for Register as data is being checked for the ITT Census publication — we wanted to avoid emails to our support teams if we could. The update made sure to include extra details about what users of the HESA collection system should do.
Preparing for future outages
We learned a couple of lessons from our recent incident that related to our maintenance page.
Firstly, not all the team was aware of the page’s existence or how to deploy it. We have now made sure the team is aware and more developers know how to use it.
Secondly, the initial content in the page related to planned maintenance from March 2022. We’ve now updated the default page to have generic outage content that can be deployed quickly. This can then be updated with an outage-specific message by our content designer as details are learned.
We’ve also updated our maintenance page with template styles and messages, so that developers have everything they need to update it quickly and independently.