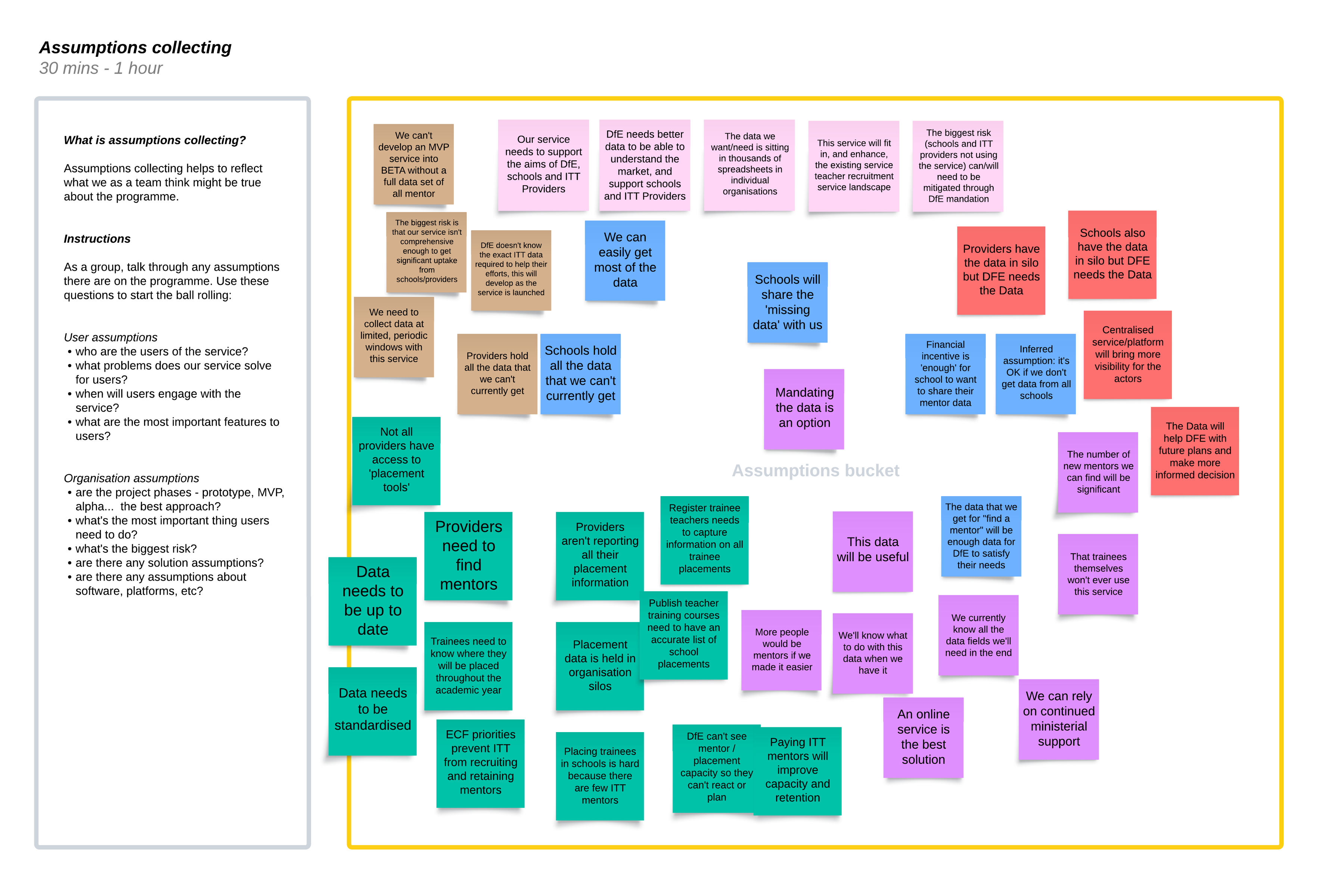
We mapped our assumptions to understand better which areas of the school placement problem space we should explore.
Assumptions can be risky if they are not openly considered and can even have costly implications if they prove unfounded or incorrect. This is why assumption mapping is such a critical step.
We asked ourselves, "What assumptions are we making?”
We collected the assumptions on a Lucid board.
We then discussed each assumption and placed them on a priority matrix with certainty and risk on the axes.
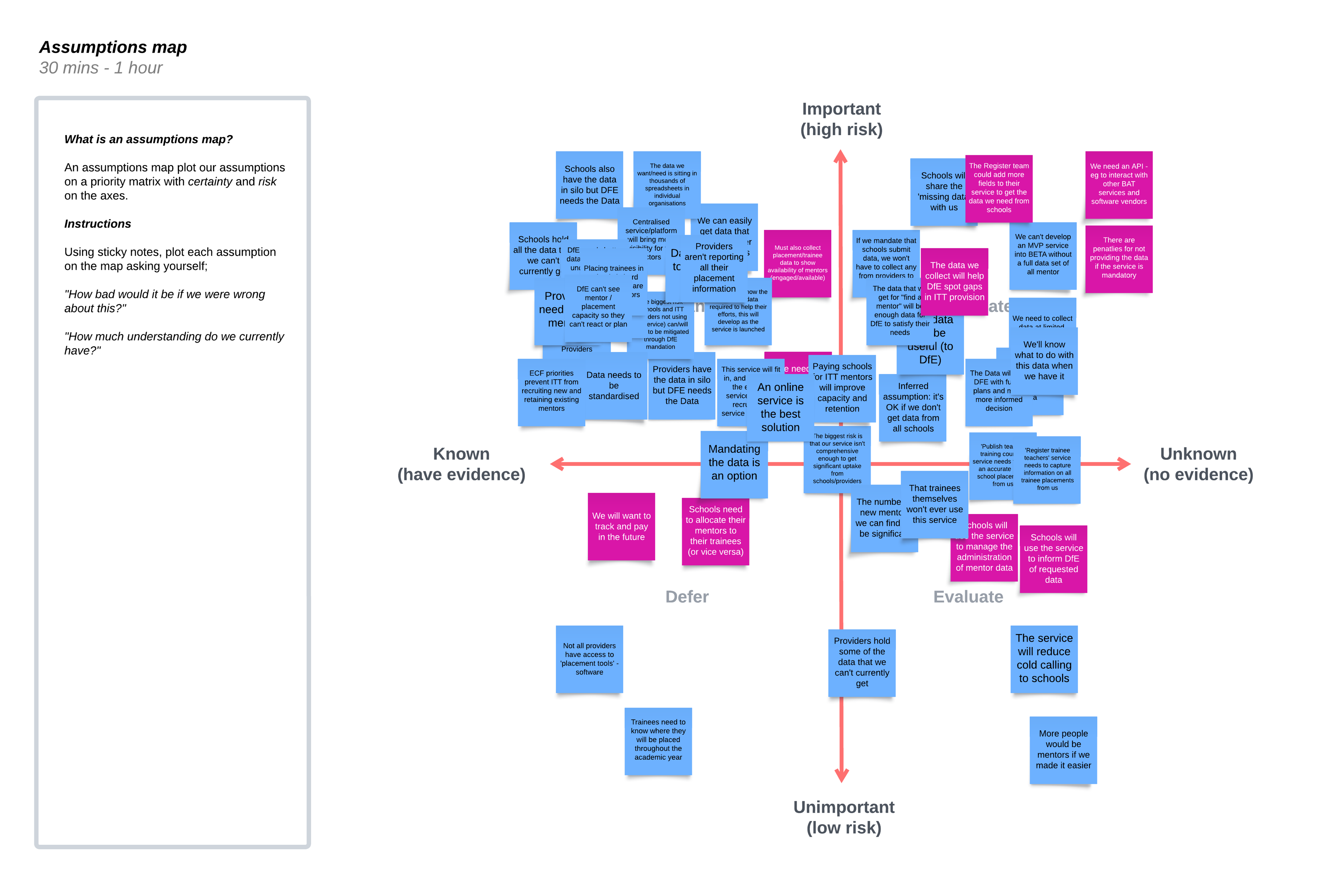
Our assumptions
We took the high-risk, unknown assumptions and collated them into categories:
- Collecting school placement data via a different service
- Collecting school placement data from schools
- Financial incentives
- DfE data use
- Minimum service requirements
- Frequency of data collection
- Service interdependencies
1. Collecting school placement data via a different service
- The Register trainee teachers (Register) team could add more fields to their service to get the data we need from schools
2. Collecting school placement data from schools
- Schools will share school placement data with us
- If we mandate that schools submit data, we will not have to collect any from providers to fill any gaps
- There are penalties for not providing the data if the service is mandatory
- A financial incentive is enough for schools to want to share their mentor data
- The most significant risk is that our service is not comprehensive enough to get sufficient uptake from schools and providers
- We can launch a service without a complete set of data
3. Financial incentives
- Paying schools for Initial Teacher Training (ITT) mentors will improve capacity and retention
4. DfE data use
- The data we collect will:
- be enough to satisfy DfE’s needs
- improve planning and decision-making
- show gaps in ITT provision
- We will know what to do with this data when we have it
5. Minimum service requirements
- We cannot develop a service without a complete set of school placement and mentor data
6. Frequency of data collection
- We need to collect data at limited, periodic windows with this service
7. Service interdependencies
- Publish teacher training courses (Publish) needs to have an accurate list of school placements from us
- Register trainee teachers (Register) needs to capture information on all trainee placements from us
- We need an API to interact with other Becoming a teacher (BAT) services and software vendors
Next steps
The next step is to plan and run experiments to test these assumptions.